A Brief History
From Mendel to the Human Genome Project











Explore Genomic Resources
Our free resource library is packed full of lesson plans, videos, interactive games and other educational content from the National Human Genome Research Institute and our partners.

Read Genomics: Insights
Read articles written by promising researchers about the science they're doing in the lab to inform, educate, and raise awareness about genetics and genomics.

1865
Gregor Mendel, the father of modern genetics, presents his research on experiments in plant hybridization
Gregor Mendel, a 19th century Augustinian monk, is called the father of modern genetics. He used a monastery garden for crossing pea plant varieties having different heights, colors, pod shapes, seed shapes, and flower positions. Mendel’s experiments, between 1856 and 1863, revealed how traits are passed down from parents. For example, when he crossed yellow peas with green peas, all the offspring peas were yellow. But when these offspring reproduced, the next generation was ¾ yellow and ¼ green. Mendel’s work, which was presented in 1865, showed that what we now call “genes” determine traits in predictable ways.

1869
Friedrich Miescher identifies "nuclein," DNA with associated proteins, from cell nuclei
Friedrich Miescher was born in Basel, Switzerland, in 1844. After completing medical school, he went to the University of Tübingen where he researched white blood cells. White blood cells are found in large quantities in infections, so Miescher collected bandages with infectious materials from a nearby clinic for his research. In 1869, he isolated a new molecule from the cells’ nuclei and called it “nuclein.” Nuclein contained hydrogen, oxygen, and a unique ratio of phosphorus to nitrogen. Although Miescher studied nuclein throughout his career, he and other scientists of that time believed proteins were the molecules by which traits passed from parents to children. The importance of nuclein (DNA) was unrecognized for many years.
1952
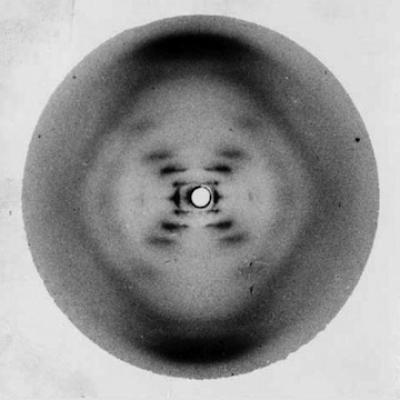
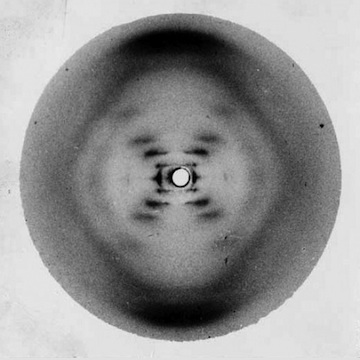
Rosalind Franklin creates Photograph 51, showing a distinctive pattern that indicates the helical shape of DNA
Rosalind Franklin was born in London in 1920. Several years after graduating from Cambridge University, she studied X-ray diffraction techniques in Paris. In 1951, Franklin accepted a research scholarship at King’s College in London where Maurice Wilkins, a physicist and molecular biologist, was using X-ray crystallography to study DNA. Franklin took two sets of high-resolution photos of crystallized DNA fibers and looked at the dimensions of DNA strands, with phosphates on the outside of what appeared to be a helical structure. Franklin’s paper on her X-ray diffraction data was published in the same issue of Nature as Watson and Crick’s paper introducing their 3-D model of DNA structure.

1953
James Watson and Francis Crick discover the double helix structure of DNA
When Francis Crick and James Watson modeled the structure of DNA, they used paper cutouts of the bases (A, C, G, T) and metal scraps from a machine shop. Their model represented DNA as a double helix, with sugars and phosphates forming the outer strands of the helix and the bases pointing into the center. Hydrogen bonds connect the bases, pairing A–T and C–G; and the two strands of the helix are parallel but oriented in opposite directions. Their 1953 paper notes that the model “immediately suggests a possible copying mechanism for the genetic material.”
1961
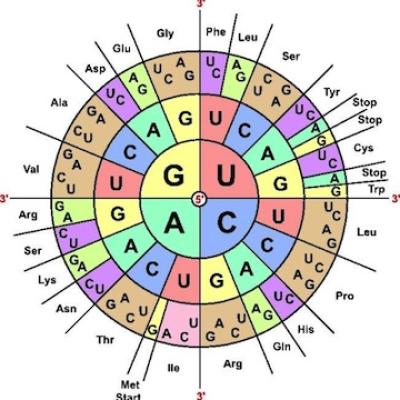
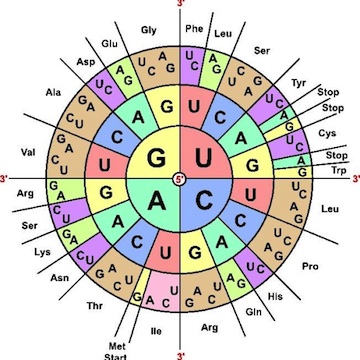
Marshall Nirenberg cracks the genetic code for protein synthesis
In the early 1960s, Marshall Nirenberg and National Institutes of Health colleagues focused on how DNA directs protein synthesis and the role of RNA in these processes. Their 1961 experiment, using a synthetic messenger RNA (mRNA) strand that contained only uracils (U), yielded a protein that contained only phenylalanines. Identifying UUU (three uracil bases in a row) as the RNA code for phenylalanine was their first breakthrough. Within a few years, Nirenberg’s team had cracked the 60 mRNA codons for all 20 amino acids. In 1968, Nirenberg shared the Nobel Prize in Physiology or Medicine for his contributions to breaking the genetic code and understanding protein synthesis.

1977
Frederick Sanger develops rapid DNA sequencing technique
In 1977, Frederick Sanger developed the classical “rapid DNA sequencing” technique, now known as the Sanger method, to determine the order of bases in a strand of DNA. Special enzymes are used to synthesize short pieces of DNA, which end when a selected “terminating” base is added to the stretch of DNA being synthesized. Typically, each of these terminating bases is tagged with a radioactive marker, so it can be identified. Then the DNA fragments, of varying lengths, are separated by how rapidly they move through a gel matrix when an electric field is applied – a technique called electrophoresis. Frederick Sanger shared the 1980 Nobel Prize in Chemistry for his contributions to DNA-sequencing methods.
1983
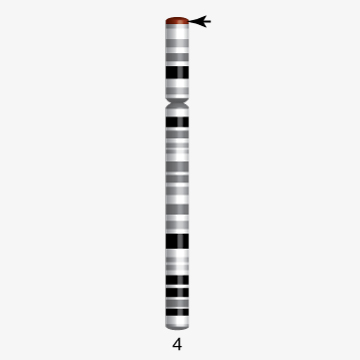
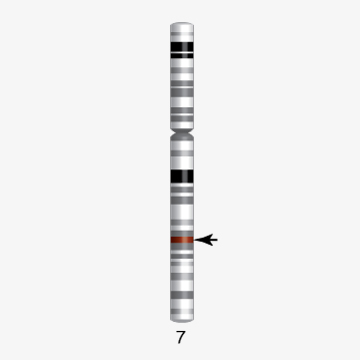
First genetic disease mapped, Huntington’s Disease
Huntington’s disease (HD) causes the death of specific neurons in the brain, leading to jerky movements, physical rigidity, and dementia. Symptoms usually appear in midlife and worsen progressively. The location of the HD gene, whose mutation causes Huntington’s disease, was mapped to chromosome 4 in 1983, making HD the first disease gene to be mapped using DNA polymorphisms – variants in the DNA sequence. The mutation consists of increasing repetitions of “CAG” in the DNA that codes for the protein huntingtin. The number of CAG repeats may increase when passed from parent to child, leading to earlier HD onset in each generation. The gene was finally isolated in 1993.
1983
Invention of polymerase chain reaction (PCR) technology for amplifying DNA
Conceived in 1983 by Kary Mullis, the Polymerase Chain Reaction (PCR) is a relatively simple and inexpensive technology used to amplify or make billions of copies of a segment of DNA. One of the most important scientific advances in molecular biology, PCR amplification is used every day to diagnose diseases, identify bacteria and viruses, and match criminals to crime scenes. PCR revolutionized the study of DNA to such an extent that Dr. Mullis was awarded the Nobel Prize in Chemistry in 1993.
1989
Cystic Fibrosis gene mutation identified
Cystic fibrosis (CF), a life-threatening genetic disease that causes thick, sticky mucus to build up in the lungs, digestive tract, pancreas, and other organs, is one of the most common chronic lung diseases in children and young adults. In the early 1980s, a number of novel laboratory tools were applied to CF to try to find the gene responsible. In June 1989, researchers identified a small DNA mutation in 70% of cystic fibrosis patients, but not in healthy individuals. The discovery of the CFTR (cystic fibrosis transmembrane conductance regulator) gene is the single most important discovery to date in CF research.
1990
First evidence provided for the existence of the BRCA1 gene
BRCA1 (BReast CAncer gene 1) is a “tumor suppressor gene,” which normally produces a protein that prevents cells from growing and dividing out of control. However, certain variations of BRCA1 can disrupt its normal function, leading to increased hereditary risk for cancer. The first evidence for existence of the BRCA1 gene was provided in 1990 by the King laboratory at University of California Berkeley. After a heated international race, the gene was finally isolated in 1994. Today, researchers have identified more than 1,000 mutations of the BRCA1 gene, many of them associated with increased risk of cancer, particularly breast and ovarian cancers in women.

1990
The Human Genome Project begins
Beginning in 1984, the U.S. Department of Energy (DOE), National Institutes of Health (NIH), and international groups held meetings about studying the human genome. In 1988, the National Research Council recommended starting a program to map the human genome. Finally, in 1990, NIH and DOE published a plan for the first five years of an expected 15-year project. The project would develop technology for analyzing DNA; map and sequence human and other genomes – including fruit flies and mice; and study related ethical, legal, and social issues.
1995
Haemophilus influenzae becomes first bacterium genome sequenced
Sequencing the genome of bacterium Haemophilus influenzae, reported in May 1995, demonstrated for the first time that random “shotgun” sequencing could be applied to whole genomes with speed and accuracy. In conventional sequencing, genomes were laboriously broken down into ordered, overlapping segments (physical maps) before sequencing efforts began. In contrast, shotgun sequencing used powerful computational software to assemble short overlapping DNA fragments, without any preliminary physical map of the genome. Within months after completion of the H. influenzae project, the same method was successfully applied to another bacterium, Mycoplasma genitalium. Since then, this method has been used to sequence the genomes of many organisms.

1996
“Bermuda Principles” drafted for Human Genome Project free data access
At a 1996 summit in Bermuda, leaders of the Human Genome Project agreed that all human genomic sequence information generated by centers funded for large-scale human sequencing should be made freely available and in the public domain within 24 hours after generation. The “Bermuda Principles” were drafted to encourage research and development and to maximize the Human Genome Project’s benefits to society – in contrast to the standard practice in scientific research of making experimental data available only after its publication. These principles reshaped the practices of an entire industry and have established rapid prepublication data release as the norm in genomics and other fields.

1998
Celera Genomics Corporation founded for sequencing the human genome
The events leading to the early completion of the human genome sequence involved the private corporation Celera Genomics – founded in 1998 by Craig Venter – and the public International Human Genome Sequencing Consortium. In this highly competitive enterprise to complete the human genome sequence, publicly funded science seeded private-sector initiatives, collaborative data sharing coexisted with competition and ownership of data, and jaw-dropping technological innovation fueled improvements in the production, assembly, and analysis of genomic data. For more than 10 years, the “race for the human genome sequence” embodied the tensions and excitement of scientists’ efforts to map and sequence the genomes of humans and other organisms.
1999
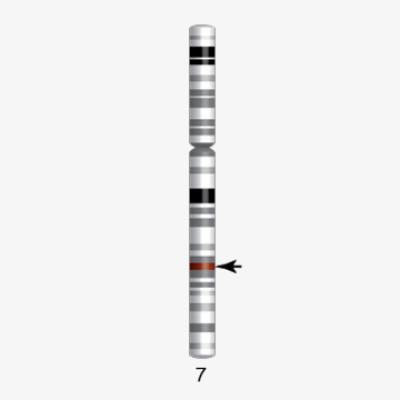
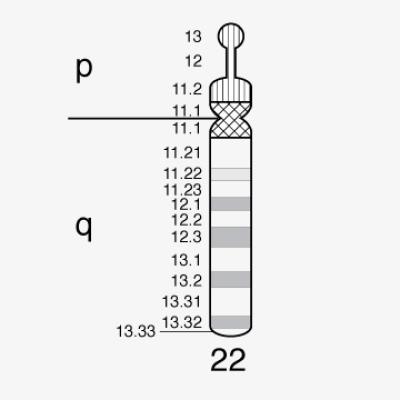
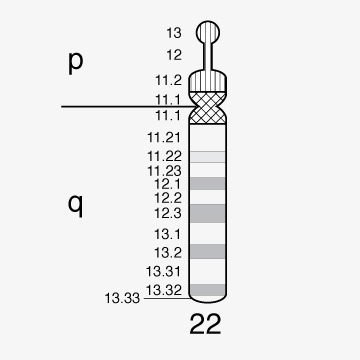
Chromosome 22 first human chromosome to be decoded
When the sequence of human Chromosome 22 was first reported in 1999, it was the longest, continuous stretch of DNA ever decoded and assembled. Chromosome 22 was chosen as the first of the 23 human chromosomes to decode because of its relatively small size and its association with several diseases. Seeing the organization of a human chromosome for the first time at the base-pair level paved the way for the rest of the Human Genome Project. Sequencing Chromosome 22 was an international collaboration between scientists in the U.S., England, Japan, France, Germany, and China.
2000
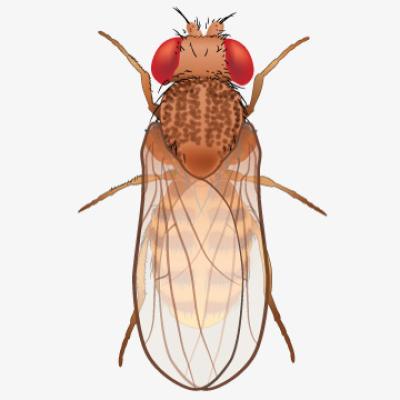
Genome sequence of model organism fruit fly reported
Organisms such as the fruit fly, Drosophila melanogaster, have been crucial for identifying the functions of human genes. In 2000, a consortium of scientists released a substantially complete fruit fly genome sequence, obtained using several different but complementary sequencing strategies. Groups at the University of California, Berkeley, and Lawrence Berkeley National Laboratory contributed about 25 percent of the sequence, as well as highly detailed genetic maps and a mapped scaffold of partial sequence. Dr. Craig Venter and colleagues at Celera Genomics contributed about 3 million random sequences and computational expertise to assemble the results.

2001
First draft of the human genome released
In 2001, the Human Genome Project international consortium published a first draft and initial analysis of the human genome sequence. At the same time, Craig Venter and colleagues working at Celera Genomics Corporation published another version of the human genome sequence. A wealth of information was obtained from the initial analysis of the human genome draft. For instance, the number of human genes was estimated to be about 30,000 (later revised to about 20,000). Researchers also reported that the DNA sequences of any two human individuals are 99.9 percent identical.
2002
Mouse becomes first mammalian research organism with decoded genome
In 2002, the international Mouse Genome Sequencing Consortium announced their publication of a high-quality draft sequence of the mouse genome. Scientists were able, for the first time, to compare and contrast the human genome sequences with those of another mammal. This milestone was all the more significant because of the widespread use of the laboratory mouse as an animal model for studying human disease. Among other informative discoveries, researchers reported that more than 90 percent of the mouse genome could be aligned with corresponding regions of the human genome, and each of the two genomes seemed to contain close to 30,000 protein-coding genes.

2003
Human Genome Project completion announced
In 2003, the Human Genome Project's ambitious goals had all been met or surpassed. The sequences produced by the Human Genome Project covered about 99 percent of the human genome's gene-containing regions. Not only was the project finished two-and-a-half years ahead of time, but it was also significantly under budget. In addition, to help researchers better understand the meaning of the human genetic instruction book, the project successfully undertook a wide range of other goals: from sequencing the genomes of organisms used in disease research, to developing new technologies for studying whole genomes. The Human Genome Project has been compared to the moon-landing project as an outstanding scientific achievement of humankind.